
Your website will be indexed in search engines and appear in search engine results pages (SERPs) only after web robots (typically search engine crawlers) inspect your website’s pages and index content on them. In such a way, they collect certain information from the site and service it to users.
In turn, a website creator needs to provide web robots with specific instructions about how to crawl pages on the website. For this purpose, they create a robots.txt file that regulates the process of crawling.

What Is a Robots.txt File?
It’s a simple text document, an explicit instruction with further actions for all web robots that crawl pages on your site. There are more than 300 different search engine robots from various associations. The best known of them are the following:
- Google Search — Googlebot
- Bing Search — Bingbot/MSN bot
- Yahoo Search — Slurp Bot
- DuckDuckGo Search — DuckDuckBot
- Baidu — Baiduspider
- Sogou — Sogou Spider
- Exalead — Exabot
- Facebook – Facebook external hit bot
- Amazon’s Alexa Internet Ranking — Ia_archiver
Why Do You Need It?
The robots.txt file is handy to control access for web robots to particular pages of your site. You can allow or disallow crawlers of specific search engines to check and index the site. Among common use cases are:
- To show access to your site for reputable associations and their user-agents;
- Forbid search engines from indexing your site while it’s at the development stage;
- To avoid duplicate content from appearing in SERPs;
- To prevent indexing of certain files on your website;
- To specify the location of sitemap(s);
- To set up a bot delay and keep your server from overloading if there are many pieces of content that crawlers need to index.

How Does Robots.txt Work?
When visiting your website, the first thing crawlers do is open the robots.txt file, which gives them instructions on moving further on your website. A site doesn’t automatically come with a robots.txt file, so you can create one with Notepad++, Sublime Text, or any other text editor and upload the file to your root directory.
With Boxmode, it’s possible to create the robots.txt file automatically. A website owner also can edit it in the dashboard, if necessary.
Rules & Symbols
A standard robots.txt file looks like this:
User-agent: *
Disallow: /
This is an example of a robots.txt file if you don’t want to let any search engine into your site. Let’s view each line in more detail.
User-agent:
In this line, you should mention the robot you appeal to. You can type in an asterisk to address all robots at once or a specific robot’s name to give instructions only to it.
Disallow:
In this line, you can specify what you prohibit. If you leave it empty, this will mean that the robot can scan the entire site. You can also add commands here to prevent robots from checking a specific folder, file, URL, or even files with a specific extension:
Disallow: /foldername/
Disallow: /user-info.html
Disallow: /images/image-1.jpg
Disallow: /images*.gif$
If there is only a slash after Disallow, the robot won’t find anything on your website. This command is usually used when the site is still under construction, and you don’t want someone to find it in the search results in an unfinished form. Make sure you remove the slash when the site is ready.
You can also refer to a particular robot and give instructions only to it. For example, it can be a Googlebot. In this case, you should write “Googlebot” on the User-agent line instead of an asterisk. If you want user-agents to crawl each page of your site thoroughly, remove the slash and leave the Disallow field empty:
User-agent: Googlebot
Disallow:
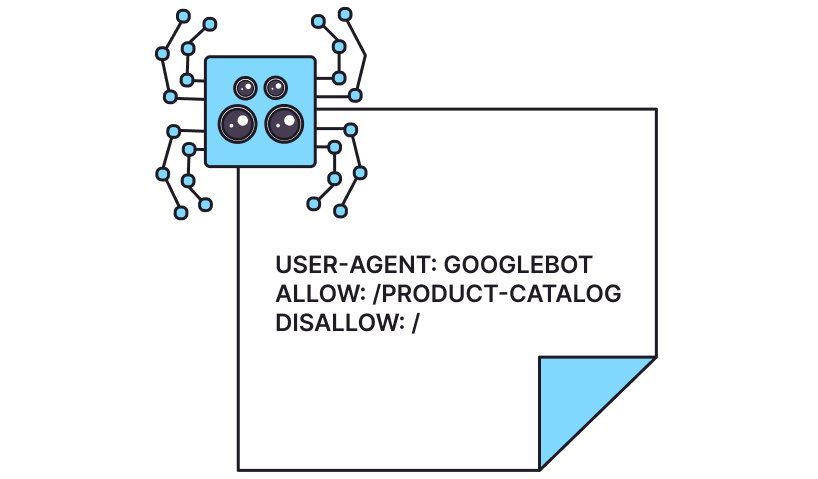
If you want to direct the robot to the specific pages on your website (for example, the Product Catalog page), you should mention them in the Allow field and restrict access to other pages (Disallow: /). It’ll look like this:
User-agent: Googlebot
Allow: /product-catalog
Disallow: /
You can specify in the robots.txt file that all site URLs required for indexing are at a specific web address. With each new visit, the user-agent checks what has changed in the file and update information about the site in the database of the search engine:
Sitemap: https://yourboxmodesite.com/sitemap.xml
What Can You Hide From Web Robots?
- Personal information of site users you don’t want robots to collect;
- Pages with various forms of sending information;
- Mirrors — pages with duplicate content;
- Search results pages;
- Dynamic product and service pages;
- Account pages;
- Admin pages;
- Shopping cart;
- Chats; and
- Thank you pages.
Why Do You Need to Hide Them?
Without a robots.txt file, your sensitive information, such as users’ personal data, can get into the search results. In a robots.txt file, you can restrict access to certain pages of the site and save the security of the data.
The second important reason why it’s worth dividing information into open and hidden areas using a robots.txt file is the so-called crawl budget that Googlebot has. In simple words, it’s the number of URLs Googlebot can crawl. Your mission is to help it spend its budget only for the most valuable pages of your site. Moreover, the results of crawling affects the ranking of the website in the search results.
Google says that the main factor that negatively influences the crawl budget is a large number of low-value-added URLs. It draws the user-agent’s attention, and Googlebot doesn’t have enough resources to go through significant and interesting content on the site.
So it’s important to use your crawl budget wisely and not let the user-agent waste resources looking at unnecessary or confidential pages on your site.
How to Avoid Common Mistakes in Robots.txt?
Follow these simple tips to avoid common mistakes:
- You should always write the name of the robots.txt file in lowercase letters;
- Place your robots.txt file in your main directory so that robots can see it;
- Specify user-agents only in the required line. Otherwise, the request will not work;
- Don’t leave the user-agent line empty. Specify the name of the bot or enter an asterisk;
- List each catalog in a new Disallow line;
- Always use the Disallow line even if it is empty;
- Always add your sitemap line at the bottom of your robots.txt file.
Robots.txt Best Practices
Among the best practices of the robots.txt file are the following:
- A web search engine caches the robots.txt content, and it usually updates the cached information several times a day. If you changed something in the file and want to refresh it faster, you can submit your robots.txt URL to a specific search engine.
- If you block certain links on the website’s pages by the robots.txt file, they won’t be viewed in SERPs. This means that the linked resources won’t be crawled and may not be indexed unless they’re also linked from other search pages.
- Don’t use a robots.txt file to protect or hide sensitive data (like private user information) from appearing in SERPs. If other pages include links to the page with confidential information, this page may still be indexed. If you want to hide your page from search results, use a different method like password protection.
- Some search engines have several user-agents. They follow the same rules, so you don’t have to specify directives for each of the search engine’s crawlers in the robots.txt file.
Boxmode Offers
Boxmode helps you set up SEO for your website and easily increases your online presence with functional tools.
Once on the dashboard, you can click the Projects tab, go to the Project Settings section, and find a robots.txt file. Click on the Edit button and create a clear step-by-step instruction for crawlers to view your site’s pages.
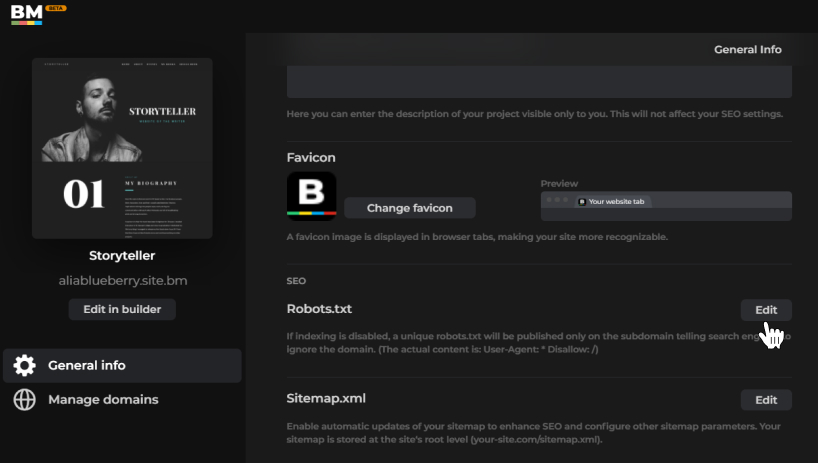
It only takes several minutes to create a perfect robots.txt file for your project built on Boxmode. With these tips, you can improve your SEO performance and benefit without any spending on ads. Just a one-time setup, and you will see a significant difference. Create your first Boxmode website and take full advantage of the robots.txt file setting today.